Двойной удар: почему хакеры полюбили заводы и торговые сети

Автор: Наталья Волчкова, руководитель отдела системного администрирования ALP ITSM
В этой статье разберем, через какие дыры чаще всего заходят злоумышленники, почему «наш ИТшник все знает» давно не работает, какие системы в реальности являются «слабым звеном» и что может сделать руководитель, чтобы не платить выкуп и не жить «от шифровальщика до шифровальщика».
Где хакеры заходят в заводы и сети
Взломы инфраструктуры в большинстве случаев — это не работа «крутой команды хакеров», которая месяцами ведет разведку и пишет уникальные эксплойты. Чаще всего это человеческий фактор и использование давно известных, но незакрытых уязвимостей.
Классический набор:
- учетные записи, за которыми никто не следит;
- простые пароли, которые не меняются годами;
- доступы к данным у сотрудников и подрядчиков, которым они уже не нужны или никогда не были нужны;
- удаленный доступ «для всех на всякий случай» без нормального контроля.
Особенно этим грешат многочисленные подрядчики по 1С, складским системам, ERP, аудиторы. На самом деле грешат не они, а ИТ‑специалисты, которые выдали доступ один раз и забыли. Внутренняя политика звучит примерно так: «антивирус тормозит и мешает», «резервные копии съедают ресурсы», «не будем усложнять», «да у нас все свои». Цена такой политики — потеря информации за годы работы и сотни человеко‑часов на ручной добор платежей и документов в 1С.
Если разобрать это технически, то картина обычно такая:
- рабочая группа вместо домена, или домен без нормальных групповых политик;
- устаревшие протоколы VPN‑доступа;
- отсутствие прозрачной матрицы прав на файлы и сервисы;
- морально и технически устаревшее оборудование, включая POS‑терминалы и складские терминалы, которые не умеют шифровать трафик и требуют «открытого» доступа к базе;
- старые ОС, «дырявый», но уникальный по функционалу софт.
Все это формирует ИТ‑ландшафт, похожий на минное поле: пока не наступил, кажется, что все нормально.
Дальше схема простая: фишинговое письмо, обиженный сотрудник, минимальные меры защиты — и вот уже перебор стандартных логинов и паролей приносит успех. А дальше все зависит от того, кто на другом конце: бот, который просто шифрует данные и оставляет кошелек для выкупа, или живой оператор, который внимательно смотрит на данные и понимает, что здесь можно зарабатывать не один раз, а шантажировать долго.
Опасные иллюзии: «у нас что‑то настроено» и «наш ИТшник все знает»
Самая частая ошибка — иллюзия, что защита уже «какая‑то есть». Это то самое «наш ИТшник там все знает, он у нас молодец».
Стоит задать несколько вопросов — и выясняется:
- процессов контроля и мониторинга нет, все держится на ручных действиях;
- резервные копии либо не делаются нормально, либо никогда не проверялись на восстановление;
- удаленный доступ выдавался «на время ковида» всем, а потом его просто не закрыли;
- новый склад просто воткнули в общую сеть, новую кассовую систему «подключили как смогли».
Средний и крупный бизнес очень часто вырастает из небольшого, из удачного стартапа. И инфраструктура растет вместе с ним, и часто не системно. Открылся новый склад — включили в общую схему. Появился новый интегратор — дали ему широкие права доступа. Во время ковида выдали удаленку всем, пандемия закончилась, а права так и остались «на всякий случай».
На производственных площадках сюда добавляется еще один слой: специализированный софт под станки и линии, написанный «во времена царя Гороха» и никем не поддерживаемый. Пока он работает — его боятся трогать. Но если управляющий таким станком компьютер шифруют или просто бьют молотком, производство встает, а восстановить среду зачастую не с чего.
Случайные сканы и целевая охота: как выбирают жертву
В интернете непрерывно работают боты и сканеры, которые по сути «простукивают» весь внешний периметр компаний. Они ищут:
- открытые RDP, VPN, базы данных;
- устройства с известными уязвимостями;
- слабые пароли и дефолтные настройки.
Если компания «светится» наружу уязвимой точкой, она может попасть под атаку просто потому, что попала в выборку. Это массовый, статистический процесс.
Дальше начинается второй слой. Для заметных игроков — заводов, крупных сетей — уже есть смысл в целенаправленном давлении. Смотрят:
- финансовый профиль и выручку;
- сезонность бизнеса;
- зависимость от непрерывности (производство, логистика, кассы);
- наличие филиалов, складов, распределительных центров.
У завода проверяют, насколько критичны окна простоя и насколько сложно ему остановить линию. У ритейла — насколько болезненны сбои в кассах и системах учета остатков. Первичный вход может быть случайным, но решение «дожимать» жертву до шифрования и выкупа — вполне целенаправленное.
Не стоит недооценивать и человеческий фактор на стороне конкуренции: перекуп сотрудников, доступ к внутренней кухне, социальная инженерия под эти данные — все это уже нормальная часть ландшафта.
Какие системы бьют больнее всего
На производстве слабым звеном часто оказывается не сама SCADA, а все, что вокруг нее:
- ПК инженеров, где крутится управляющий софт;
- удаленный доступ подрядчиков, которые обслуживают линии;
- серверы, к которым подключены эти системы;
- отсутствие сегментации: производственный контур «зашит» в общую офисную сеть.
В торговле список выглядит иначе, но принципы те же:
- POS‑контур (кассы и терминалы);
- ERP, где живут заказы, остатки, цены;
- системы управления складом и логистикой;
- сайты, порталы, личные кабинеты поставщиков.
Атака по кассам видна сразу и болезненна, но ее можно частично обойти — перейти в упрощенный режим, пробивать офлайн и донести чеки позже. А вот потеря ERP или системы склада ломает все: нельзя планировать поставки, пополнять полки, отгружать заказы.
Реальный пример: у клиента на 12 часов практически встал завод, потому что была зашифрована ключевая 1С‑база. В нее нужно было загружать сведения о произведенной продукции и оттуда забирать данные по заказам. Формально «сломалась 1С». Фактически — на полдня остановился весь производственно‑логистический цикл.
Если смотреть прагматично, «слабое звено» — это не обязательно самая старая система. Это та система, потеря которой сильнее всего бьет по прибыли.
Фишинг и социнженерия: директор из мессенджера и «налоговая» во входящих
Фишинг в промышленности и ритейле выглядит очень буднично — и поэтому эффективно.
Достаточно письма от «поставщика», «логиста», «службы безопасности», «налоговой», «техподдержки» или даже «руководителя». В эпоху мессенджеров добавляются сообщения и звонки от «директора». Настоящий директор уходит в отпуск, и вдруг главному бухгалтеру пишет «директор» в мессенджер: «Нужно срочно оплатить счет, я забыл, потом связи не будет». Понятно, что нужно «прямо сейчас». И сотни тысяч уходят неизвестно кому.
В промышленности и торговле люди работают в режиме постоянного ответа на счета, накладные, графики поставок. Проверять каждое письмо по второму каналу кажется лишней бюрократией. На этом и строится атака.
Сегодня фишинг стал заметно качественнее:
- грамотный язык;
- домены‑двойники;
- вложения, похожие на реальные бизнес‑документы;
- иногда еще и предварительный звонок.
Отдельный риск 2026 года — использование AI для подготовки писем, сценариев общения и даже имитации голоса. Это уже не фантастика, а рабочие инструменты атакующих.
Мошенничество бьет по бюджету и репутации. Плюс добавляет головную боль в виде проверок, объяснительных и необходимости доказывать, что компания не финансирует «не тех людей». На этом фоне специализированная защита почты и регулярные тренировки по кибергигиене выглядят очень недорогим решением.
Сколько стоит день простоя и почему иногда платят выкуп
Универсальной цифры нет: разброс огромный. Для части МСБ в России при хорошем резервировании и понятной архитектуре простой после атаки шифровальщика может уложиться в день‑два. Если заражение ушло глубоко, а резервные копии либо недоступны, либо тоже задеты, речь идет уже о неделях простоя, сорванных контрактах и реальной угрозе бизнесу.
Практически это считают так:
Потери от простоя = (годовая выручка ÷ рабочее время в году) × доля процессов, завязанных на пострадавшие системы × часы простоя.
Если критичные ИТ‑системы обслуживают 70–80% оборота, даже несколько часов могут вылиться в очень неприятную сумму. Плюс поверх прямых потерь появляются штрафы, переработки, срочные доработки, ускоренное восстановление.
Если нужны ориентиры масштаба, открытые кейсы в ритейле показывают, что у крупных сетей один день простоя может стоить сотни миллионов рублей: так, в 2024 году сбой в работе ритейлера «Верный» оценивали в 120–140 млн рублей в день, а три дня простоя сети «Винлаб» — примерно в 1 млрд рублей потерь.
В нашей практике был кейс завода, который встал посреди рабочего дня: зашифровали ключевую 1С‑базу, через которую шли заказы и учет произведенной продукции. На момент обращения часть систем уже была недоступна, сотрудники фактически не могли ни отгружать товар, ни планировать производство. Клиенту предложили заплатить выкуп, чтобы «быстрее вернуться к работе». Мы сразу выступили против: завод давно был у нас на сопровождении, система резервного копирования спроектирована и реализована нами, регулярные тесты восстановления проводились, и мы доверяли этой схеме.
В итоге был брошен усиленный состав инженеров, поднят отдельный «чистый» контур, куда за 12 часов восстановили критичные сервисы из проверенных копий. Завод вернулся к работе без выплаты выкупа. По деньгам оказалось, что стоимость внедрения нормальной системы резервного копирования + аварийного восстановления была в несколько раз ниже суммы выкупа, не говоря уже о том, что выкуп не дал бы никаких гарантий сохранности данных и защиты от повторной атаки.
Почему же многие компании все‑таки платят? Причина почти всегда в математике:
- простой обходится в десятки миллионов,
- резервных копий нет или они сомнительны,
- восстановление «по‑честному» занимает недели,
- задеты критичные данные: разработки, проектная документация, финансовые базы, заказы, логистика.
В такой ситуации руководство начинает рассматривать выкуп как один из сценариев снижения потерь. Особенно когда нет ни DRP, ни отработанных процедур восстановления, и каждый день простоя — это реальные минусы в отчете.
У этой логики есть несколько неприятных «но»:
- выкуп не гарантирует рабочего дешифратора;
- не гарантирует, что все расшифруют до конца и быстро;
- не гарантирует, что украденные данные не всплывут в даркнете;
- не гарантирует, что компанию не атакуют повторно — как раз наоборот, успешный платеж делает ее привлекательной целью.
Фактически компания платит за шанс, но не за результат. Зрелые команды смотрят шире: оценивают, что именно зашифровано, что есть в офлайне, можно ли подняться поэтапно, какова реальная глубина компрометации и какие юридические и репутационные последствия будет иметь такой платеж. И, что важнее всего, инвестируют в архитектуру, бэкапы и DRP до инцидента, чтобы в критический момент иметь альтернативу, кроме перевода денег на кошелек злоумышленников, что может быть расценено налоговыми и регулирующими органами как финансирование недружественных стран.
Почему компании шифруют снова и снова
Большинство обращений к экспертам приходит не «до», а уже во время или после атаки. Не когда строят устойчивость, а когда кассы уже не работают, серверы зашифрованы, а на экранах пользователей висит записка с номером кошелька.
Это системная проблема рынка: профилактика кажется дорогой и лишней. В результате значимая часть запросов — это реактивная помощь: локализация, восстановление, расследование.
Самые показательные истории — не про «одну большую атаку», а про компании, которые шифруются регулярно. Раз в 3–6 месяцев. Каждый такой эпизод внутри воспринимается как отдельная трагедия, а не как следствие того, что инфраструктура и процессы так и остались на том же уровне, что и в момент первого инцидента.
Типичный сценарий выглядит так:
- Компания попадает под шифровальщика. Встает производство, ломаются кассы, сотрудники несколько дней работают в режиме хаоса и бумажек.
- Приезжает внешняя команда, помогает локализовать заражение, восстановить критичные сервисы — иногда из бэкапов, иногда «с нуля», с переустановкой серверов и приложений.
- По итогам специалисты честно выдают список рекомендаций: что нужно сделать прямо сейчас, что — в ближайшие месяцы, чтобы снизить риск повторения истории.
- Руководство смотрит на этот список, кивает, благодарит — и откладывает внедрение «до лучших времен»: сезон, запуск нового проекта, нет людей, нет бюджета.
Через 3–6 месяцев тот же клиент возвращается: «нас снова зашифровали». Вектор атаки часто похожий, уязвимости — те же: открытые удаленные доступы, непроверенные бэкапы, устаревшие системы, избыток прав у пользователей и подрядчиков. Снова восстановление, снова план изменений, снова откладывание «на потом».
Были кейсы, когда такая картина повторялась несколько циклов подряд. Мы приезжали, поднимали инфраструктуру, формировали список изменений по архитектуре, доступам, резервированию, мониторингу. Клиент уходил «делать сам» и возвращался только к следующему крупному инциденту. До тех пор, пока внутри не появлялось политическое решение: «хватит жить в вечном пожаре, давайте один раз сделаем нормально».
В этих историях важен не столько уровень конкретной защиты, сколько сам подход. Ни один разовый инцидент сам по себе не лечит системные проблемы. Если не менять архитектуру, не внедрять DRP, не наладить нормальные бэкапы и кибергигиену, компания остается ровно в той точке, где ее нашли в первый раз. И злоумышленникам достаточно снова нажать на те же кнопки, чтобы запустить знакомый сценарий еще раз.
DRP и бэкапы: когда кажется, что они есть
Самая частая ошибка с планом аварийного восстановления (DRP) — считать его красивой папкой для аудиторов. Рабочий DRP — это не схема в презентации, а очень конкретный ответ на вопросы:
- что будет, если завтра сгорит единственный сервер;
- что будет, если зашифруют все общие папки;
- что будет, если затопит серверную;
- что будет, если уволенный сотрудник удалит документы с сетевого диска;
- что будет, если умрет диск на ПК бухгалтера, где «для спокойствия» живут все базы 1С.
Кто будет поднимать системы? Откуда? В какой последовательности? Сколько это займет времени?
Разработка DRP начинается с приоритета: какие сервисы критичны, от недоступности каких компания пострадает быстрее всего. На это уже ложатся цифры RTO/RPO — допустимое время простоя и допустимая потеря данных.
С резервным копированием история похожая. Абсолютно неуязвимых схем нет, но есть базовые принципы, которые радикально повышают шансы пережить атаку:
- правило 3‑2‑1: не менее трех копий, на двух типах носителей, одна — вне основного контура;
- регулярные тесты восстановления, а не просто отчеты «бэкап прошел успешно».
Шутка «сисадмины делятся на тех, кто не делает бэкапы; кто уже делает; и тех, кто проверяет» — написана кровью и убытками. Копия, которую ни разу не поднимали в тесте, — это не защита, а надежда.
Особенно болезненно компании переживают потерю не «просто файлов», а уникальных операционных данных: историю заказов, остатки продукции, взаиморасчеты, рецептуры, проекты, архивы договоров, интеграционные справочники. В этот момент бизнес откатывается не просто на пару дней — он теряет часть собственной памяти.
Люди и культура: почему одна ошибка не должна убивать бизнес
Кибергигиена для сотрудников — это не про героические многочасовые лекции раз в год. Рабочий минимум выглядит так:
- не открывать вложения и ссылки «на автомате»;
- проверять нетипичные запросы по второму каналу (перезвонить, уточнить);
- не использовать один и тот же пароль везде;
- не запрашивать себе повышенные права «для удобства»;
- включать MFA везде, где это предлагают;
- не ставить софт и не подключать носители без согласования;
- не пересылать рабочие данные в личные мессенджеры и почту.
Но кибергигиена не работает, если сотрудника наказывают за «лишнюю осторожность». Если бухгалтеру неловко перепроверить «директора», а инженеру страшно сообщить о странном поведении станции, компания сама выращивает инцидент.
Нужен понятный «112 для ИБ (информационной безопасности)» внутри: канал, куда можно быстро сообщить о подозрении и не бояться, что за это накажут. На практике лучше всего работают короткие регулярные тренировки, а не редкие вебинары «для галочки».
Что делать компании, которая только начинает выстраивать защиту
Начинать нужно не с покупки «коробок», а с понимания себя.
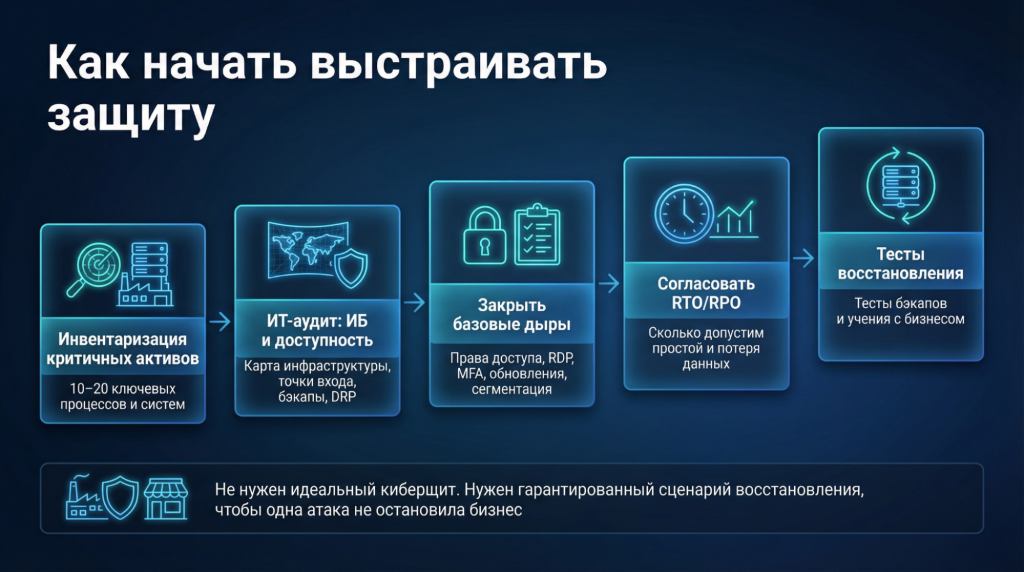
Трезвый порядок шагов:
- Определить 10–20 критичных активов и процессов: что остановит бизнес быстрее всего и где хранятся ключевые данные.
- Провести ИТ‑аудит с упором на ИБ и высокую доступность: снять карту инфраструктуры, найти точки входа, оценить резервное копирование и DRP (если есть).
- Закрыть базовые дыры: пересмотреть права доступа, убрать открытый RDP, внедрить MFA, обновить наиболее «дырявые» системы, сегментировать сеть, защитить резервные копии, настроить мониторинг ключевых событий.
- Договориться внутри бизнеса, что считается приемлемым простоем и потерей данных. Без этого любые цифры RTO/RPO — «для отчета», а не для решений. На основе согласованных требований — сформировать или актуализировать DRP.
- Выстроить регулярные тесты восстановления: раз в квартал — точечные проверки критичных систем, раз в полгода — сценарные тренировки, раз в год — полноценные учения с участием не только ИТ, но и бизнеса.
Компании не нужен «идеальный киберщит». Ей нужно не потерять бизнес из‑за самой простой атаки и иметь гарантированный сценарий восстановления без паники.
Один совет для CEO
Не относитесь к кибербезопасности как к лишней статье расходов и второстепенной функции ИТ‑отдела. Кибератака сегодня — это не про «какой‑то вирус в компьютерах». Это про остановку линии, сбой поставок, неработающие кассы, сорванные контракты, утечку клиентских данных, претензии регуляторов и прямые финансовые потери.
Если совет должен быть один, он такой: в компании должны четко знать три вещи — что для бизнеса критично, как это защищено и как это будет восстановлено, если защита не сработает. Все остальное — следствие этой управленческой зрелости.
Кибератаки нельзя «запретить приказом», но можно сильно снизить их последствия. Для этого ИТ‑руководителю нужен не еще один отчет по антивирусу, а честная картинка: какие системы у вас критичны, где реальные дыры и сколько стоит час простоя именно для вашего бизнеса. После такой инвентаризации проще выбивать бюджет не на «абстрактную безопасность», а на очень конкретные вещи — сегментацию, бэкапы, DRP и наведение порядка с удаленным доступом.
Если вы по описанию узнали свою компанию — не обязательно сразу заходить в большой, дорогой проект. Начните с короткого экспресс‑аудита: точки входа, права доступа, резервное копирование, план восстановления. Часто этого достаточно, чтобы увидеть несколько очевидных рисков, закрытие которых стоит дешевле, чем один день остановки завода или сбоя кассового контура.