«Офис встал, почта не работает»: как мы за 2 часа 47 минут восстановили критический сервис для фармкомпании после скрытого сбоя в облаке
Утро, 9:17. В нашу службу поддержки поступает заявка: «У меня и у моих коллег не работает почта». Для нашего клиента, компании из сферы фармацевтики, это означает остановку ключевых бизнес-процессов. Весь документооборот и коммуникации с партнерами парализованы. Самое тревожное — наша система мониторинга показывает, что все серверы в норме.

Рассказываем, как мы распутали этот «тихий» инцидент, восстановили сервис менее чем за три часа и использовали ситуацию, чтобы сделать IT-инфраструктуру клиента еще надежнее.
Дано: требовательный клиент и наш системный подход к IT-сопровождению
Клиент — производитель и дистрибьютор фармацевтической продукции, с которым мы работаем по договору IT-аутсорсинга с 2024 года. Несмотря на небольшой штат (около 70 пользователей), компания отличается высокой интенсивностью IT-процессов.
Наша работа с самого начала строится на принципах ITIL и глубоком погружении в инфраструктуру клиента. Это позволяет нам не просто реагировать на инциденты, а проактивно управлять IT-средой.
Наша зона ответственности
Для этой компании мы обеспечиваем полный цикл IT-поддержки:
- 1-я линия: решение бытовых вопросов пользователей (проблемы с почтой, интернетом, принтерами).
- 2-я и 3-я линии: администрирование серверной инфраструктуры и управление IT-процессами.
Наши процессы выстроены на основе практик ITIL, что включает решение инцидентов, запросов на обслуживание и управление изменениями.
Персональная база знаний — фундамент нашей работы
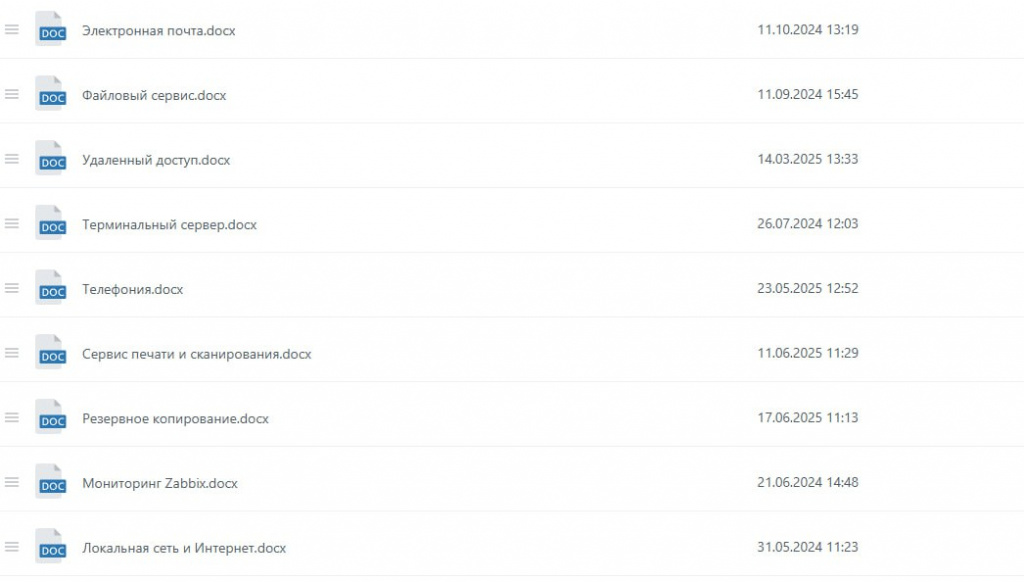
Для каждого клиента мы создаем и ведем подробную централизованную базу знаний. Это не просто склад документов, а живой инструмент, который позволяет нам действовать быстро и точно. Процесс начинается еще до старта обслуживания. Наши инженеры выезжают на место, проводят полный аудит ИТ-инфраструктуры, фотографируют оборудование, серверные стойки и документируют все до мелочей. На основе собранной информации формируется карта сети и наполняется персональная база знаний клиента.
В эту базу входит:
- Техническая документация: детальное описание всех сервисов, адреса серверов, лицензии, ключи.
- Организационная информация: контакты интернет-провайдеров, детали договоров, ответственные лица.
- Пошаговые инструкции: регламенты по типовым задачам, например, по настройке нового рабочего места или телефона.
Такой подход позволяет нашим инженерам быстро погружаться в контекст, сокращать время на диагностику и действовать максимально эффективно.
Специфика работы с клиентом:
- Комплексная среда. Мы поддерживаем унаследованную IT-архитектуру со взаимодействием нескольких юридических лиц. Это требует от нас глубокого понимания бизнес-процессов и четкой координации действий, в том числе со смежными IT-службами клиента.
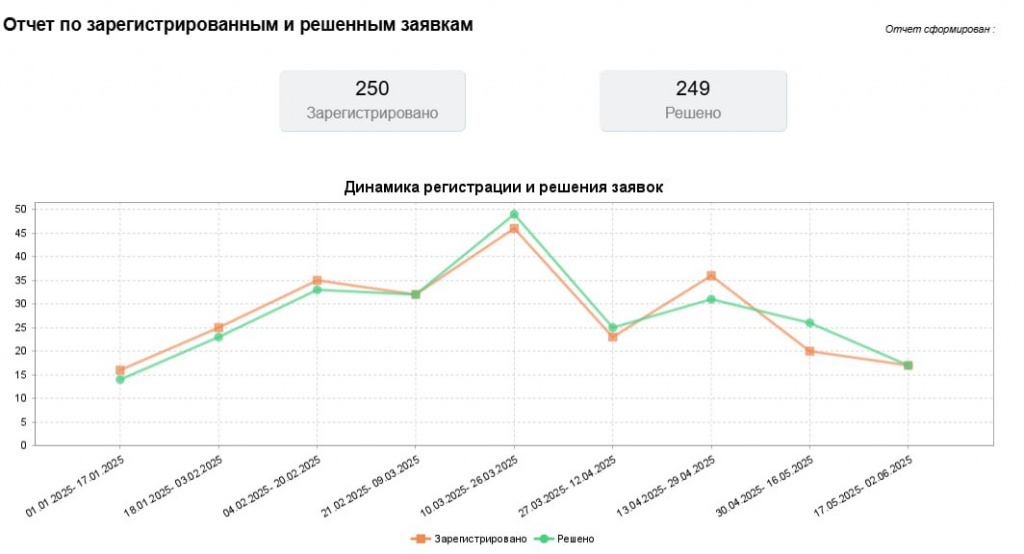
- Финансовые гарантии по SLA. Мы работаем в рамках строгих обязательств по соглашению об уровне сервиса (SLA), включая финансовую ответственность за их соблюдение. IT-директор клиента тщательно контролирует эти показатели, и мы на ежемесячной основе предоставляем ему детальный отчет с полным перечнем работ и анализом SLA.
- Взвешенный подход к модернизации. Клиент подходит к новым предложениям с определенной долей консерватизма, предпочитая проверенные решения. Для нас это означает, что каждая рекомендация должна быть максимально аргументированной и подкрепленной данными, чтобы доказать свою целесообразность.
Инцидент: «тихий» сбой, который не видит мониторинг
Ночью на оборудовании облачного провайдера произошел сбой. Виртуальная машина с почтовым сервером клиента была аварийно мигрирована на другое «железо».
Наша система мониторинга зафиксировала кратковременное прерывание доступности, утром сервер был доступен по сети, ключевые службы MS Exchange имели статус «Running». Технически все выглядело рабочим. Но по факту сервис не функционировал. О проблеме мы узнали только в 09:17 из заявки клиента.
Инцидент показал, что мониторинг «здоровья» сервера недостаточен — необходимо контролировать реальную работоспособность бизнес-сервиса.
Решение: ключевые шаги по восстановлению
Наши процессы реагирования на массовые сбои отлажены: заявка автоматически получает высший приоритет, информируется IT-менеджер, а к решению немедленно подключаются инженеры второй линии.
Ключевые этапы работ:
- Быстрая эскалация. Поняв, что проблема массовая, уже через 14 минут после первой заявки мы эскалировали задачу на подразделение системных администраторов.
- Поиск истинной причины. Первичная диагностика показала ночную перезагрузку и ошибки сертификатов. Глубокий анализ выявил корневую проблему: из-за аварийной миграции в облаке виртуальная машина потеряла сетевую связь с единственным контроллером домена, на который опиралась вся инфраструктура. Не получив конфигурацию из Active Directory, почтовый сервер Exchange некорректно перевыпустил внутренние сертификаты, что и парализовало его работу.
- Восстановление сервиса. Инженеры вручную восстановили сетевую связность, пересоздали сертификаты, перенастроили коннекторы и конфигурацию служб. Сначала удалось восстановить внутреннюю работу почты и доступ через Outlook, а затем — и внешнюю отправку/получение писем.
Итог: С момента поступления первой заявки до полного восстановления работоспособности почты прошло 2 часа 47 минут.
Стало: не просто исправление, а система предотвращения рисков
Просто починить — не наш подход. Для нас каждый серьезный инцидент — это точка роста, которая запускает внутренний процесс анализа post mortem. По итогам критичного инцидента мы подготовили детальный отчет с разбором причин и планом улучшений, а также запустили пересмотр собственных процессов, чтобы предотвратить подобные сбои в будущем.

Что мы сделали после восстановления:
- Прокачали систему мониторинга. Мы поняли слабое место нашего подхода. Сейчас наши инженеры разрабатывают вариант слежения за реальной работоспособностью сервиса, а не просто состоянием служб — так мы сможем узнавать о проблемах раньше клиента.
- Усилили аргументацию по защите инфраструктуры. Этот инцидент стал наглядным подтверждением нашей рекомендации — внедрить второй контроллер домена. Ранее клиент откладывал это решение, однако сбой показал важность резервирования.
- Выстроили прямую коммуникацию с провайдером. Мы начали переговоры с облачным провайдером, чтобы получать уведомления о технических работах и сбоях. Это позволит нам действовать на опережение и приступать к решению проблем раньше, чем они затронут бизнес клиента.
- Предложили стратегические улучшения. Мы подготовили для клиента рекомендации по долгосрочному развитию: от разработки плана аварийного восстановления (Disaster Recovery Plan) до рассмотрения перехода на более надежные облачные почтовые сервисы.
Выводы: ценность подрядчика — в реакции на непредвиденное
Этот кейс — яркий пример того, как работает зрелый IT-аутсорсинг. Проблемы случаются у всех, даже у надежных облачных провайдеров. Ценность подрядчика проявляется не в отсутствии инцидентов, а в том, как он на них реагирует.
Мы не просто восстановили сервис, но и превратили сбой в точку роста:
- Для клиента: риски подобных простоев в будущем значительно снижены, а мы в очередной раз доказали свою экспертизу через детальный и прозрачный разбор инцидента.
- Для нас: мы выявили зону роста в своих процессах и уже внедряем более совершенную систему мониторинга для всех наших клиентов.
Именно такой подход, основанный на анализе, прозрачности и постоянном совершенствовании, позволяет нам эффективно обслуживать сложные IT-инфраструктуры и быть надежным партнером даже для самых требовательных клиентов.