План аварийного восстановления (DRP): почему наличие бэкапов не гарантирует спасение бизнеса
В этой статье мы уйдем от технических деталей и поговорим на языке управленческих рисков. Вы узнаете, почему резервное копирование — это не то же самое, что восстановление работы, и как за 15 минут проверить, готов ли ваш бизнес пережить реальную цифровую катастрофу.


Автор: Авдей Мартынович, руководитель направления SMB в ALP ITSM
Иллюзия безопасности: «У нас же есть резервные копии»
Представьте ситуацию: разгар рабочего дня, отгрузки идут, колл-центр принимает звонки. Внезапно зависает 1С, отключается почта, файловый сервер недоступен. ИТ-отдел сообщает о сбое сервера или атаке вируса-шифровальщика. Бизнес встал.
Первая реакция руководителя: «Восстанавливайте из бэкапов, мы же платим за это!».
И здесь часто вскрывается критическая проблема: бэкап (файл с данными) у компании есть, а вот плана аварийного восстановления (DRP — Disaster Recovery Plan) нет. Разница между этими понятиями колоссальная, и ее непонимание может стоить компании жизни.
Бэкап vs DRP: в чем разница?
Давайте проведем аналогию с автомобилем.
- Бэкап — это запасное колесо в багажнике.
- DRP (План восстановления) — это наличие домкрата, умение водителя менять колесо и способность сделать это на оживленной трассе под дождем за 15 минут, чтобы успеть на встречу.
Если у вас есть запаска, но она завалена вещами, нет инструментов или вы не умеете ей пользоваться — наличие самого колеса бесполезно. Вы никуда не поедете.
В ИТ так же: наличие копии базы данных не означает, что завтра утром ваш офис сможет работать.
Цена вопроса: RTO и RPO на языке денег
Прежде чем требовать от ИТ-отдела «мгновенного восстановления», посчитайте деньги.

Эффективность любого плана аварийного восстановления (Disaster Recovery) определяется двумя ключевыми параметрами. Это условия сделки между бизнесом и ИТ.
RPO (Recovery Point Objective): Сколько данных мы готовы потерять?
Этот показатель отвечает на вопрос: «К какому моменту в прошлом мы должны вернуться?».
- Пример: Для интернет-магазина RPO в 15 минут означает, что при аварии пропадут только заказы за последние 15 минут.
- Риск: Если RPO равен 24 часам, вы рискуете потерять выручку и данные за целый рабочий день.
Важно: Чем меньше RPO (минуты или секунды), тем дороже технологии защиты. «Ноль потерь» стоит очень дорого.
RTO (Recovery Time Objective): Как долго мы можем не работать?
Это максимальное время простоя. Вопрос звучит так: «Через сколько часов после сбоя мы обязаны открыться?».
- Пример: Для онлайн-банка RTO — это минуты. Каждая минута простоя — прямые убытки.
- Пример: Для внутреннего архива документов RTO может составлять 24 часа — бизнес от этого не умрет.
Если вам нужен низкий RTO (восстановление за минуты), обычные бэкапы не помогут. Потребуются резервные площадки и дублирующие сервера (горячий резерв).
Как определить RTO и RPO: диалог бизнеса и IT
Нельзя просто сказать «хочу, чтобы всё работало всегда». Это всегда компромисс:
- Бизнес выдвигает требования («Хотим, чтобы работало через 10 минут»).
- ИТ-департамент считает смету («Для этого нужно купить второй сервер за 2 млн рублей»).
- Топ-менеджмент принимает решение («Ок, 2 млн — это дорого. Давайте согласимся на простой в 4 часа, но сэкономим бюджет»).
Итоговые цифры RTO и RPO — это фундамент вашего договора с ИТ-отделом.
4 сценария, когда бэкапы есть, а бизнеса нет
По опыту наших аудитов, компании теряют данные и деньги не из-за отсутствия копий, а из-за невозможности их оперативно использовать. Вот самые частые причины провалов:
- «Инфраструктурный тупик». Сервер сгорел физически или изъят. Данные сохранены на внешнем диске. Но чтобы запустить бизнес, нужно куда-то развернуть эти данные. Нового сервера нет, поставка оборудования займет время. Данные целы, но компания простаивает и теряет миллионы.
- «Бэкап-пустышка». Система резервного копирования годами отправляла отчеты «Успешно». Но по факту копировалась пустая папка или поврежденный файл базы данных. В момент аварии выясняется, что восстанавливать нечего.
- «Слишком долгое ожидание». Копия есть. Но чтобы вернуть работоспособность, админу нужно найти «железо», установить ОС, сделать необходимые настройки. Этот процесс «с нуля» занимает 2–3 дня. Готов ли ваш бизнес к такому простою?
- «Атака на бэкапы». Современные вирусы-вымогатели сначала сканируют сеть, находят и шифруют резервные копии, и только потом атакуют «боевые» сервера. Если копии лежали в общем доступе — вы потеряли всё.
Вывод: Ваша цель — не сам факт копирования, а гарантированное время восстановления сервиса (RTO — Recovery Time Objective). Именно это обеспечивает DRP.
Технический аудит руками собственника: 5 неудобных вопросов
Вам не нужно быть экспертом в ИТ, чтобы найти критические уязвимости в безопасности своей компании. Достаточно задать своему ИТ-директору или системному администратору правильные вопросы.
Сделайте это на ближайшей планерке. Ответы (или их отсутствие) скажут вам о состоянии дел больше, чем любые отчеты.
Вопрос № 1: «Где физически лежат наши копии?»
Этот вопрос проверяет, защищены ли вы от физической потери данных (пожар, кража, изъятие серверов).
| Правильный ответ | Красный флаг |
|---|---|
| «Мы соблюдаем правило 3-2-1. У нас есть 3 копии данных, на 2 разных носителях, и одна копия обязательно хранится вне офиса (в облаке или другом дата-центре)». | «На том же сервере, просто на диске D», «На внешнем диске, который лежит на сервере», «В соседнем кабинете». Если сгорит офис или зашифрует вирус — вы потеряете и оригинал, и копию. |
Вопрос № 2: «Мы делаем копии файлов или образы всей системы?»
Этот вопрос про скорость восстановления (RTO).
| Правильный ответ | Красный флаг |
|---|---|
| «Мы делаем полные образы (Snapshots) критичных серверов. Если сервер упадет, мы просто развернем этот образ на любом другом железе за пару часов». | «Просто копируем файлы 1С и документы». Это значит, что в случае аварии админу придется вручную устанавливать Windows, драйверы, программы, настраивать сеть и безопасность. Это 2-3 дня простоя вместо пары часов. |
Вопрос № 3: «Есть ли у нас резервное железо (Warm Standby)?»
Представим худшее: ваш основной сервер вышел из строя окончательно. Куда вы будете разворачивать ваши (даже идеальные) бэкапы?
| Правильный ответ | Красный флаг |
|---|---|
| «У нас есть арендованный ресурс в облаке / старый, но рабочий сервер в запасе. Он слабее основного, но потянет критические процессы, пока мы ищем замену». | «Ну... побежим покупать новый». В текущих реалиях логистики поставка серверного оборудования может занять недели. |
Вопрос № 4: «Как наши бэкапы защищены от шифровальщиков?»
Вирусы-вымогатели — угроза № 1 для малого и среднего бизнеса.
| Правильный ответ | Красный флаг |
|---|---|
| «У нас используется immutable-хранилище (неизменяемое) или оффлайн-копии (диски, которые физически отключаются от сети после записи)». | «Они лежат в папке „Backups“ в общей сети». Вирус найдет эту папку за секунду и зашифрует её вместе с базой данных. |
Вопрос № 5: «Когда мы последний раз реально пробовали восстановиться?»
Самый главный вопрос.
| Правильный ответ | Красный флаг |
|---|---|
| «В прошлом квартале. Мы подняли копию в тестовой среде, бухгалтер зашел и проверил остатки. Всё работало». | «Бэкапы делаются каждую ночь, ошибки не приходят». Отсутствие ошибок записи не гарантирует, что данные внутри целы. |
«Цифровая аптечка» собственника
В момент кризиса часто царит хаос: телефоны не отвечают, ключевые сотрудники недоступны. Чтобы не потерять контроль над бизнесом, у вас должен быть «Аварийный пакет» (лучше в бумажном виде в сейфе).
Что в него входит:
- Карта коммуникаций. Кто принимает решение о переходе на резерв? Кому звонить, если штатный ИТ-отдел не на связи? Контакты провайдеров, хостинга, интеграторов.
- Мастер-пароли. Конверт с актуальными доступами уровня Administrator/Root. Это ключи от вашей собственности: серверов, облака, панели управления доменом. Без них вы заложник ситуации.
-
Приоритеты восстановления. ИТ-специалисты должны знать, что чинить в первую очередь. Пример:
- Приоритет 0 (Критично): 1С, CRM, телефония.
- Приоритет 1 (Важно): Почта, файловый обменник.
- Приоритет 2 (Терпит): Архив документов, корпоративный портал.
Парадокс «Бэкапа Шрёдингера»
Пока вы не попытались восстановить данные из резервной копии, считайте, что ее не существует. Файл бэкапа может быть создан, иметь актуальную дату и вес, но внутри содержать поврежденную структуру данных.
Как избежать иллюзий? Внедрить регламент учений.
Не верьте отчетам программного обеспечения. Введите правило: раз в квартал или хотя бы раз в полгода проводится «боевое» учение.
- Бэкап разворачивается в изолированной среде («песочнице»).
- Проводится проверка функциональности: открывается ли база, проводятся ли документы.
- Фиксируется реальное время восстановления.
Только успешный тест превращает вашу надежду на спасение в гарантированный инструмент.
Почему важен План аварийного восстановления
Построение отказоустойчивой системы (DRP) — это не разовая задача и не магия. Это скучный, системный бизнес-процесс.
Что можно сделать прямо сейчас:
- Проведите 15-минутный разговор с вашим ИТ-руководителем по списку вопросов из этой статьи.
- Убедитесь, что у вас есть физический доступ к мастер-паролям от вашей инфраструктуры.
- Назначьте дату ближайших учений по восстановлению из бэкапа.
Лучше потратить ресурсы на планирование сегодня, чем потерять бизнес завтра.
Шаблон плана аварийного восстановления можно скачать по ссылке.
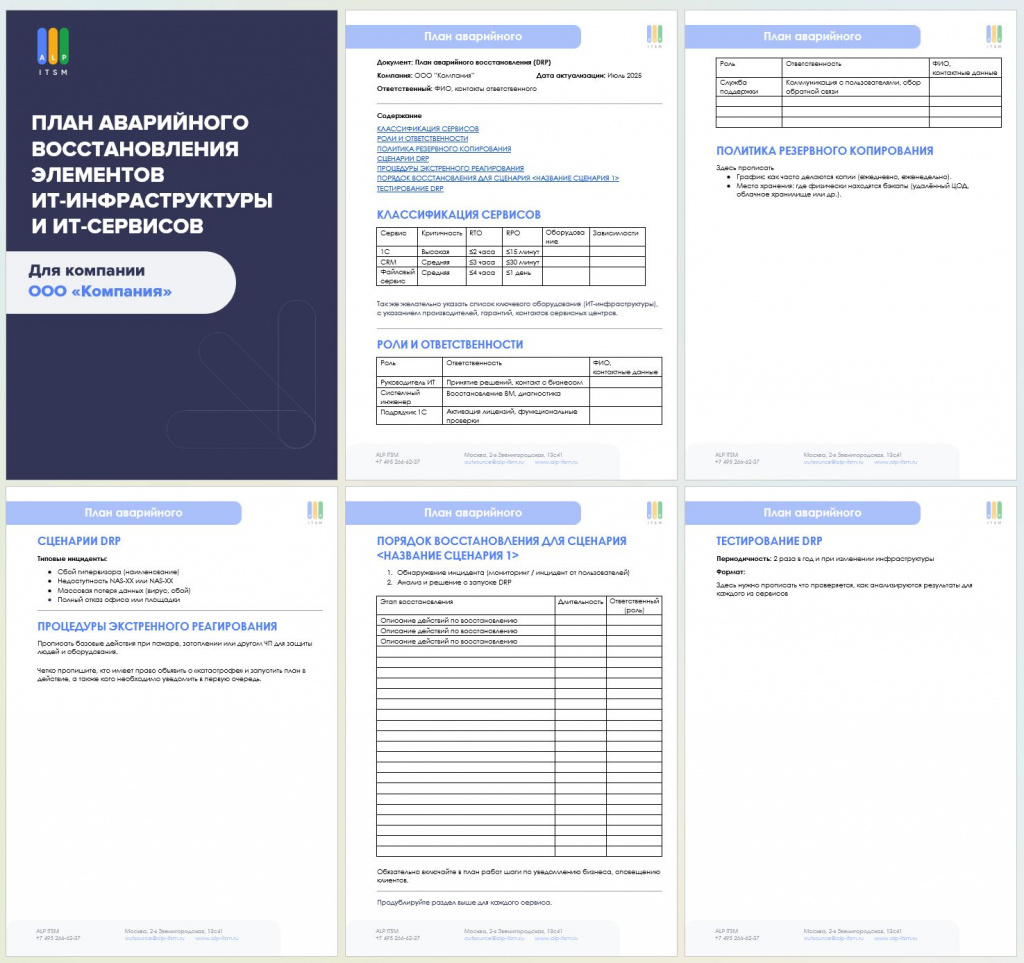
Нужна помощь в аудите ИТ-инфраструктуры или построении DRP?
Эксперты ALP ITSM готовы провести независимую оценку вашей системы резервного копирования и разработать план, который гарантирует непрерывность вашего бизнеса.